How to Scrape Indeed Data: Jobs, Salaries, and more.
In this article, you will discover the easiest way to scrape jobs data from Indeed with Page2API.

Introduction
Indeed.com is a job board that aggregates postings, allowing users to search for specific positions.
Why may we need to web scrape Indeed? Collecting job listings from Indeed will help us to:
- search for hirings
- analyze the demand for specific job positions
- analyze the average salaries
Prerequisites
To start scraping Indeed jobs, we will need the following things:
- A Page2API account
- A job position in a specific location that we are about to scrape.
In our case, we will search for Ruby On Rails Software Engineer in Redwood City, CA, and set the area to within 10 miles.
How to scrape Indeed Jobs
First what we need is to open indeed.com and type Ruby On Rails Software Engineer into the search input from the Indeed home page and pick the location we need.
This will change the browser URL to something similar to:
https://www.indeed.com/jobs?q=Ruby%20On%20Rails%20Software%20Engineer&l=Redwood%20City%2C%20CA&radius=10
The URL is the first parameter we need to perform the scraping.
The page that you see must look like the following one:
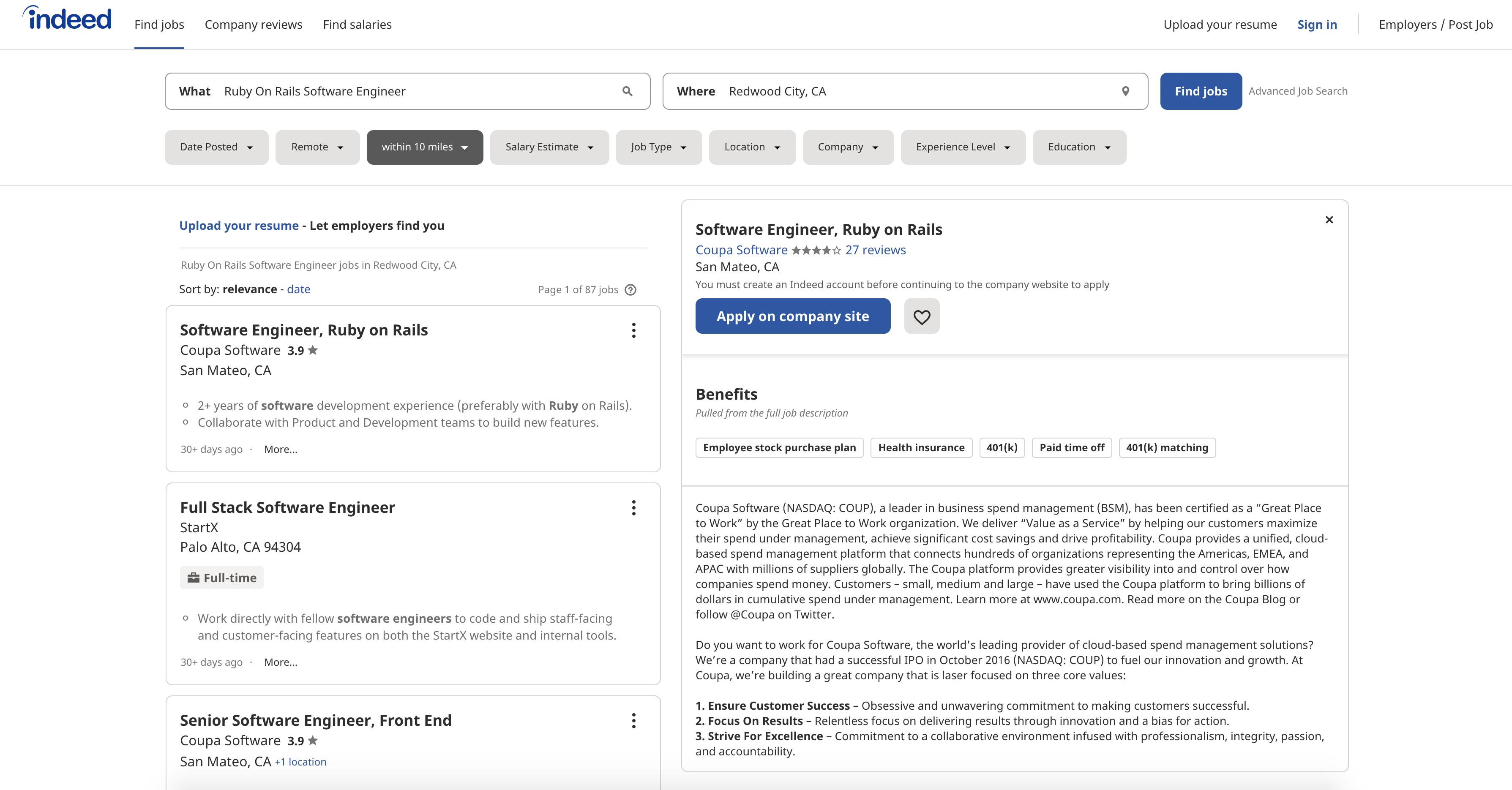
If you inspect the page HTML, you will find out that a single result is wrapped into an element that looks like the following:
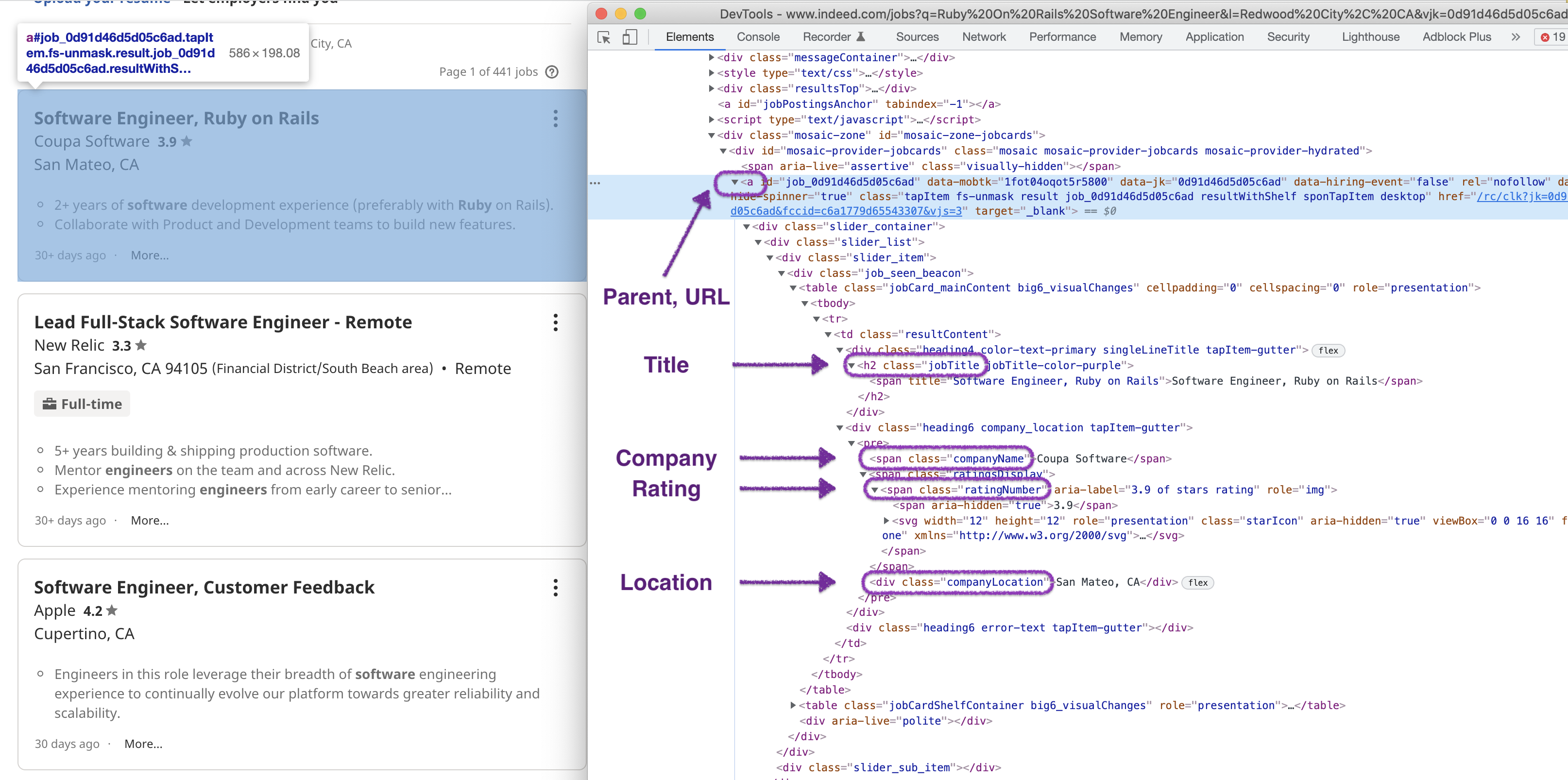
From this page, we will scrape the following attributes from each Indeed job posting:
- Title
- URL
- Company
- Location
- Rating
- Additional info
Now, let's define the selectors for each attribute.
/* Parent: */
a.result
/* Title */
h2.jobTitle
/* URL */
a.result
/* Company */
.companyName
/* Location */
.companyLocation
/* Rating */
.ratingNumber span[aria-hidden=true]
/* Additional info */
.metadata div
It's time to handle the pagination.
To go to the next page, we must click on the next page link if it's present on the page:
var next = document.querySelector('a[aria-label=Next]'); if(next) { next.click() }
// we have this simple check to avoid any javascript errors (in case the Next page button is missing)
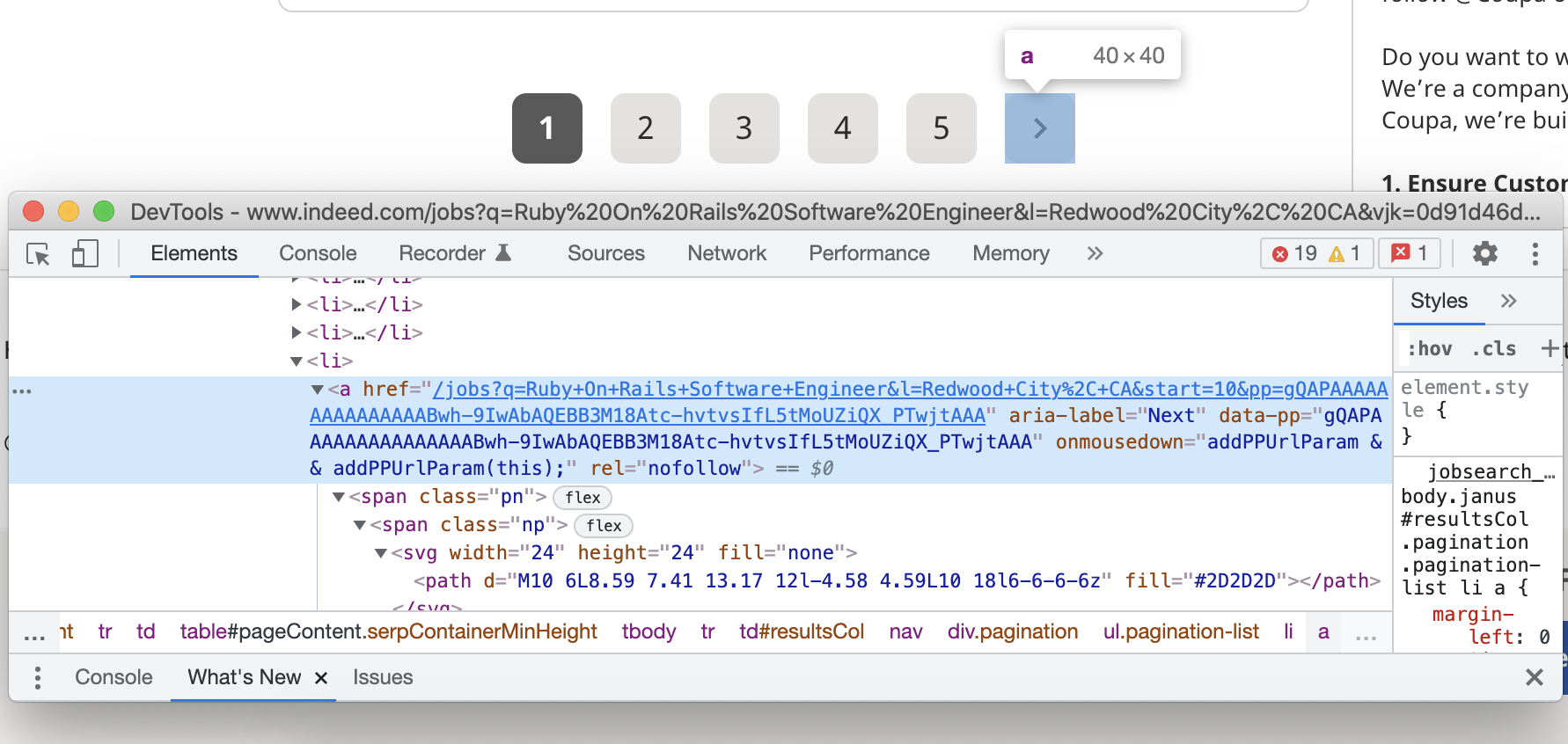
The scraping will continue while the Next link is present on the page, and stop if it disappears. The stop condition for the scraper will be the following javascript snippet:
document.querySelector('a[aria-label=Next]') == null
Let's build the request that will scrape all the results that the search page returned.
The payload for our scraping request will be:
{
"url": "https://www.indeed.com/jobs?q=Ruby%20On%20Rails%20Software%20Engineer&l=Redwood%20City%2C%20CA&radius=10",
"real_browser": true,
"merge_loops": true,
"scenario": [
{
"loop": [
{
"wait_for": "a.result"
},
{
"execute": "parse"
},
{
"execute_js": "var next = document.querySelector('a[aria-label=Next]'); if(next) { next.click() }"
}
],
"stop_condition": "document.querySelector('a[aria-label=Next]') == null"
}
],
"parse": {
"jobs": [
{
"_parent": "a.result",
"url": "_parent >> href",
"title": "h2.jobTitle >> text",
"company": ".companyName >> text",
"location": ".companyLocation >> text",
"rating": ".ratingNumber span[aria-hidden=true] >> text",
"additional_info": [
".metadata div >> text"
]
}
]
}
}
Setting the api_key as an environment variable:
export API_KEY=YOUR_PAGE2API_KEY
Running the scraping request with cURL:
curl -v -XPOST -H "Content-type: application/json" -d '{
"api_key": "'"$API_KEY"'",
"url": "https://www.indeed.com/jobs?q=Ruby%20On%20Rails%20Software%20Engineer&l=Redwood%20City%2C%20CA&radius=10",
"merge_loops": true,
"real_browser": true,
"scenario": [
{
"loop": [
{ "wait_for": "a.result" },
{ "execute": "parse" },
{ "execute_js": "var next = document.querySelector(\"a[aria-label=Next]\"); if(next) { next.click() }" }
],
"stop_condition": "document.querySelector(\"a[aria-label=Next]\") == null"
}
],
"parse": {
"jobs": [
{
"_parent": "a.result",
"url": "_parent >> href",
"title": "h2.jobTitle >> text",
"company": ".companyName >> text",
"location": ".companyLocation >> text",
"rating": ".ratingNumber span[aria-hidden=true] >> text",
"additional_info": [
".metadata div >> text"
]
}
]
}
}' 'https://www.page2api.com/api/v1/scrape' | python -mjson.tool
The result:
{
"result": {
"places": [
{
"url": "https://www.indeed.com/company/Coupa/jobs/Senior-Lead-Software-Engineer-fa676bc66ad1daae?fccid=c6a1779d65543307&vjs=3",
"title": "Senior/Lead Software Engineer, Ruby on Rails",
"company": "Coupa Software",
"location": "San Mateo, CA 94402 (Nineteenth Avenue area)+1 location",
"rating": "3.9",
"additional_info": [
"$145,000 - $165,000 a year",
"Full-time",
"8 hour shift"
]
},
{
"url": "https://www.indeed.com/company/Poshmark/jobs/Software-Engineer-e55c033766067a6c?fccid=0f4f2d112db7d324&vjs=3",
"title": "Software Engineer, Web Applications",
"company": "Poshmark",
"location": "Redwood City, CA",
"rating": "4.6",
"additional_info": [
"Full-time",
]
},
{
"url": "https://www.indeed.com/rc/clk?jk=0d91d46d5d05c6ad&fccid=c6a1779d65543307&vjs=3",
"title": "Software Engineer, Ruby on Rails",
"company": "Coupa Software",
"location": "San Mateo, CA",
"rating": "3.9",
"additional_info": [
"Remote",
]
}, ...
]
}, ...
}
How to scrape Indeed Job Page
We need to open any URL from the previous step with the job listing in a new tab.
This will change the browser URL to something similar to:
https://www.indeed.com/viewjob?jk=0d91d46d5d05c6ad
This URL is the first parameter we need to scrape all the information about a job.
The page that you see must look like the following one:
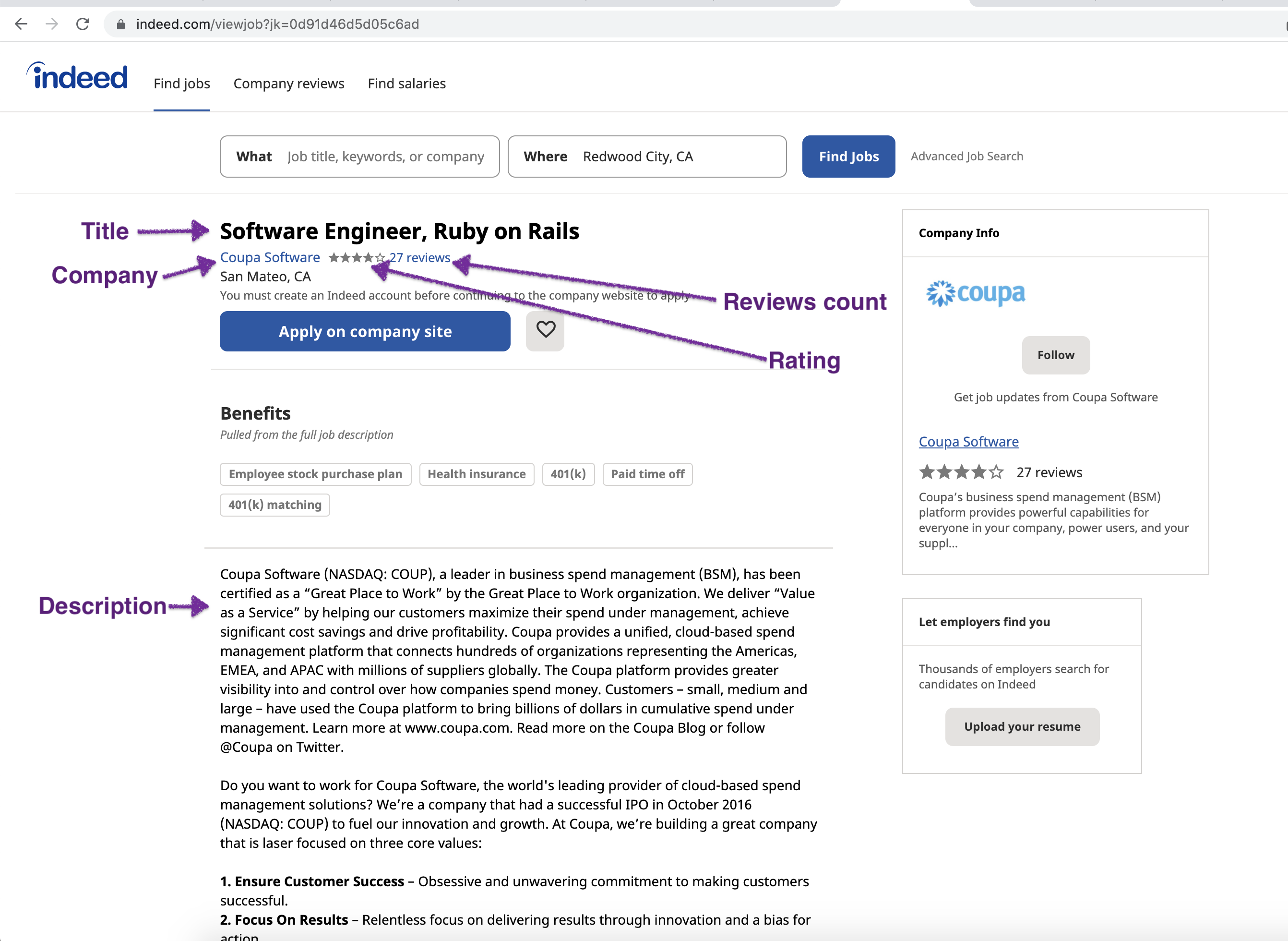
From this page, we will scrape the following attributes:
- Title
- Company
- Rating
- Reviews count
- Description
Now, let's define the selectors for each attribute.
/* Title */
h1
/* Company */
.jobsearch-InlineCompanyRating a
/* Rating */
meta[itemprop=ratingValue]
/* Reviews count */
meta[itemprop=ratingCount]
/* Description */
#jobDescriptionText
It's time to prepare the request that will scrape Indeed Job Page.
The payload for our scraping request will be:
{
"url": "https://www.indeed.com/viewjob?jk=0d91d46d5d05c6ad",
"parse": {
"title": "h1 >> text",
"company": ".jobsearch-InlineCompanyRating a >> text",
"rating": "meta[itemprop=ratingValue] >> content",
"reviews_count": "meta[itemprop=ratingCount] >> content",
"description": "#jobDescriptionText >> text"
}
}
Running the scraping request with cURL:
curl -v -XPOST -H "Content-type: application/json" -d '{
"api_key": "'"$API_KEY"'",
"url": "https://www.indeed.com/viewjob?jk=0d91d46d5d05c6ad",
"parse": {
"title": "h1 >> text",
"company": ".jobsearch-InlineCompanyRating a >> text",
"rating": "meta[itemprop=ratingValue] >> content",
"reviews_count": "meta[itemprop=ratingCount] >> content",
"description": "#jobDescriptionText >> text"
}
}' 'https://www.page2api.com/api/v1/scrape' | python -mjson.tool
The result:
{
"result": {
"title": "Software Engineer, Ruby on Rails",
"company": "Coupa Software",
"rating": "3.9",
"reviews_count": "27",
"description": "Coupa Software (NASDAQ: COUP), a leader in business spend management (BSM), ..."
}, ...
}
Conclusion
That's pretty much of it!
In this article, you've learned how to scrape the data from a job board such as Indeed.com with Page2API - a Web Scraping API that handles all the hassle, and lets you get the data you need with ease.
The original article can be found here: